6 results
(View BibTeX file of all listed publications)
2019
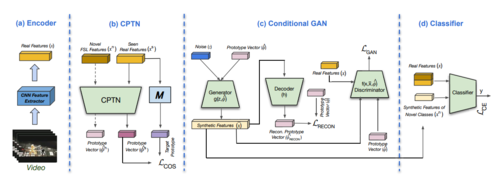
ProtoGAN: Towards Few Shot Learning for Action Recognition
Dwivedi, S. K., Gupta, V., Mitra, R., Ahmed, S., Jain, A.
Proc. International Conference on Computer Vision (ICCV) Workshops, October 2019 (manual)
Few-shot learning (FSL) for action recognition is a challenging task of recognizing novel action categories which are represented by few instances in the training data. In a more generalized FSL setting (G-FSL), both seen as well as novel action categories need to be recognized. Conventional classifiers suffer due to inadequate data in FSL setting and inherent bias towards seen action categories in G-FSL setting. In this paper, we address this problem by proposing a novel ProtoGAN framework which synthesizes additional examples for novel categories by conditioning a conditional generative adversarial network with class prototype vectors. These class prototype vectors are learnt using a Class Prototype Transfer Network (CPTN) from examples of seen categories. Our synthesized examples for a novel class are semantically similar to real examples belonging to that class and is used to train a model exhibiting better generalization towards novel classes. We support our claim by performing extensive experiments on three datasets: UCF101, HMDB51 and Olympic-Sports. To the best of our knowledge, we are the first to report the results for G-FSL and provide a strong benchmark for future research. We also outperform the state-of-the-art method in FSL for all the aforementioned datasets.
2015

Proceedings of the 37th German Conference on Pattern Recognition
Gall, J., Gehler, P., Leibe, B.
Springer, German Conference on Pattern Recognition, October 2015 (proceedings)
2014

Advanced Structured Prediction
Nowozin, S., Gehler, P. V., Jancsary, J., Lampert, C. H.
Advanced Structured Prediction, pages: 432, Neural Information Processing Series, MIT Press, November 2014 (book)
The goal of structured prediction is to build machine learning models that predict relational information that itself has structure, such as being composed of multiple interrelated parts. These models, which reflect prior knowledge, task-specific relations, and constraints, are used in fields including computer vision, speech recognition, natural language processing, and computational biology. They can carry out such tasks as predicting a natural language sentence, or segmenting an image into meaningful components.
These models are expressive and powerful, but exact computation is often intractable. A broad research effort in recent years has aimed at designing structured prediction models and approximate inference and learning procedures that are computationally efficient. This volume offers an overview of this recent research in order to make the work accessible to a broader research community. The chapters, by leading researchers in the field, cover a range of topics, including research trends, the linear programming relaxation approach, innovations in probabilistic modeling, recent theoretical progress, and resource-aware learning.

Human Pose Estimation from Video and Inertial Sensors
Ph.D Thesis, -, 2014 (book)
The analysis and understanding of human movement is central to many applications
such as sports science, medical diagnosis and movie production. The ability to
automatically monitor human activity in security sensitive areas such as airports,
lobbies or borders is of great practical importance. Furthermore, automatic
pose estimation from images leverages the processing
and understanding of massive digital libraries available on the Internet.
We build upon a model based approach where the human shape is modelled with a surface mesh
and the motion is parametrized by a kinematic chain. We then seek for the pose
of the model that best explains the available observations coming from different sensors.
In a first scenario, we consider a calibrated mult-iview setup in an indoor studio. To obtain very accurate
results, we propose a novel tracker that combines information coming from video and a
small set of Inertial Measurement Units (IMUs). We do so by locally optimizing a joint
energy consisting of a term that measures the likelihood of the video data and a term
for the IMU data. This is the first work to successfully combine video and IMUs
information for full body pose estimation. When compared to commercial marker based systems
the proposed solution is more cost efficient and less intrusive for the user.
In a second scenario, we relax the assumption of an indoor studio and we tackle outdoor scenes
with background clutter, illumination changes, large recording volumes and difficult motions
of people interacting with objects. Again, we combine information from video and IMUs.
Here we employ a particle based optimization approach
that allows us to be more robust to tracking failures. To satisfy the orientation constraints
imposed by the IMUs, we derive an analytic Inverse Kinematics (IK) procedure to sample from the manifold
of valid poses. The generated hypothesis come from a lower dimensional manifold and therefore the computational
cost can be reduced. Experiments on challenging sequences suggest the proposed tracker can be applied
to capture in outdoor scenarios. Furthermore, the proposed IK sampling procedure can be used
to integrate any kind of constraints derived from the environment.
Finally, we consider the most challenging possible scenario: pose estimation of monocular images.
Here, we argue that estimating the pose to the degree of accuracy as in an engineered environment is
too ambitious with the current technology. Therefore, we propose to extract meaningful semantic information about
the pose directly from image features in a discriminative fashion. In particular, we introduce posebits
which are semantic pose descriptors about the geometric relationships between parts in the body.
The experiments
show that the intermediate step of inferring posebits from images can improve pose estimation from
monocular imagery. Furthermore, posebits can be very useful as input feature for many computer vision
algorithms.
2012

Consumer Depth Cameras for Computer Vision - Research Topics and Applications
Fossati, A., Gall, J., Grabner, H., Ren, X., Konolige, K.
Advances in Computer Vision and Pattern Recognition, Springer, 2012 (book)
2008

GNU Octave Manual Version 3
John W. Eaton, David Bateman, Soren Hauberg
Network Theory Ltd., October 2008 (book)