Optimization problems arising in intelligent systems are similar to those studied in other fields (such as operations research, control, and computational physics), but they have some prominent features that set them apart, and which are not addressed by classic optimization methods. Numerical optimization is a domain where probabilistic numerical methods offer a particularly interesting theoretical contribution.
One key issue is computational noise. Big Data problems often have the property that computational precision can be traded off against computational cost. One of the most widely occuring problem structure is that one has to find a (local) optimum of a function $L$ that is the sum of many similar terms, each arising from an individual data point $y_i$
$$L(x) = \frac{1}{N}\sum_{i = 1} ^N \ell(y_i,x) $$
Examples of this problem include the training of neural networks, of logistic regressors, and many other linear and nonlinear regression/classification algorithms. If the dataset is very large or even infinite, it is impossible, or at least inefficient, to evaluate the entire sum. Instead, one draws $M\ll N$ (hopefully representative) samples $y_j$ from some distribution and computes the approximation
$$\hat{L}(x) = \frac{1}{M} \sum_{j=1} ^M \ell(y_j,x) \approx L(x)$$
If the representers $y_j$ are drawn independently and identically from some distribution, then this approximation deviates, relative to the true $L(x)$, by an approximately Gaussian disturbance.
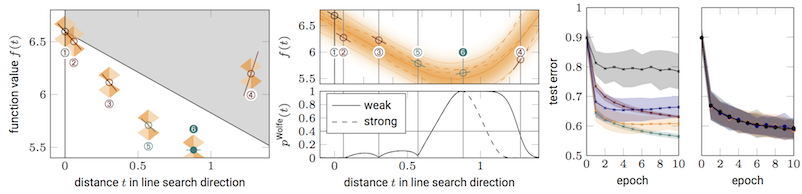
Classic optimizers like quasi-Newton methods are unstable to these disturbances, hence the popularity of first-order methods, like stochastic gradient descent (sgd), in deep learning. But even such simple methods become harder to use in the stochastic domain. In particular, sgd and its variants exhibit free parameters (e.g. step-sizes / learning rates) in the stochastic setting, even though such parameters can be easily tuned automatically in the noise-free case. Thus, even at the world's leading large AI companies, highly trained engineers spent their work time hand-tuning parameters by repeatedly running the same training routine on high-performance hardware. A very wasteful use of both human and hardware resources. A NeurIPS workshop organized by us in 2016 highlighted the urgency of this issue.
The probabilistic perspective offers a clean way to capture this issue: It simply amounts to changing the likelihood term of the computation from a point measure on $L(x)$ to a Gaussian distribution $p(\hat{L}\mid L) = \mathcal{N}(\hat{L};L,\Sigma)$. This seemingly straightforward formulation immediately offers an analytical avenue to understand why existing optimizers fundamentally require hand-tuning: While a point measure only has a single parameter (the location), a Gaussian has two parameters: mean and (co-) variance. But the latter does not feature in classic analysis, and is simply unknown to the algorithm. It is possible to show [ ] that this lack of information can make certain parameters (such as step sizes) fundamentally un-identified. Identifying them not just requires new algorithms, but also concretely computing a new object: In addition to batch gradients, also batch square gradients, to empirically estimate the variance. Doing so is not free, but it has low and bounded computational cost [ ], because it can re-use the back-prop pass, the most expensive part of deep learning training steps.
Over years we have built a series of tools that use this additional quantity to tune various learning hyperparameters such as the learning rate [ ] [ ] [ ], batch size [ ] and stopping criterion [ ]. We have also contributed theoretical analysis for some of the most popular deep learning optimizers [ ] and are now working towards a new code platform for the automation of deep learning in the inner loop, to free practitioners hands to build models, rather than tune algorithms.