2024

HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
(Accepted as Highlight: Top 11.9%)
Fan, Z., Parelli, M., Kadoglou, M. E., Kocabas, M., Chen, X., Black, M. J., Hilliges, O.
Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2024 (conference) Accepted

AMUSE: Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Chhatre, K., Daněček, R., Athanasiou, N., Becherini, G., Peters, C., Black, M. J., Bolkart, T.
Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2024 (conference) To be published
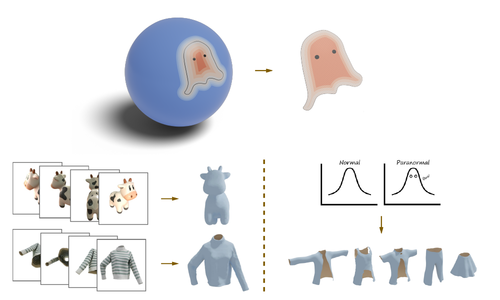
Ghost on the Shell: An Expressive Representation of General 3D Shapes
(Oral)
Liu, Z., Feng, Y., Xiu, Y., Liu, W., Paull, L., Black, M. J., Schölkopf, B.
In Proceedings of the Twelfth International Conference on Learning Representations, May 2024 (inproceedings) Accepted
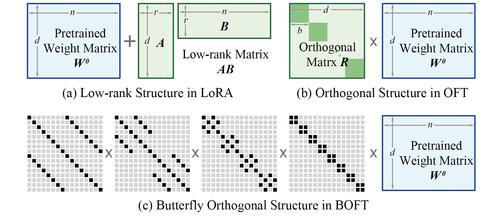
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Liu, W., Qiu, Z., Feng, Y., Xiu, Y., Xue, Y., Yu, L., Feng, H., Liu, Z., Heo, J., Peng, S., Wen, Y., Black, M. J., Weller, A., Schölkopf, B.
In Proceedings of the Twelfth International Conference on Learning Representations, May 2024 (inproceedings) Accepted

TADA! Text to Animatable Digital Avatars
Liao, T., Yi, H., Xiu, Y., Tang, J., Huang, Y., Thies, J., Black, M. J.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings) Accepted

POCO: 3D Pose and Shape Estimation using Confidence
Dwivedi, S. K., Schmid, C., Yi, H., Black, M. J., Tzionas, D.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings)

TECA: Text-Guided Generation and Editing of Compositional 3D Avatars
Zhang, H., Feng, Y., Kulits, P., Wen, Y., Thies, J., Black, M. J.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings) To be published
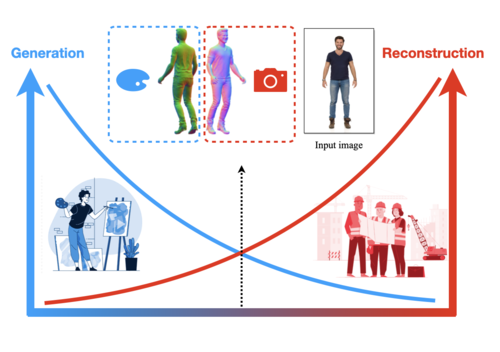
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Huang, Y., Yi, H., Xiu, Y., Liao, T., Tang, J., Cai, D., Thies, J.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings) Accepted

ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation
Zhang, H., Christen, S., Fan, Z., Zheng, L., Hwangbo, J., Song, J., Hilliges, O.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings) Accepted
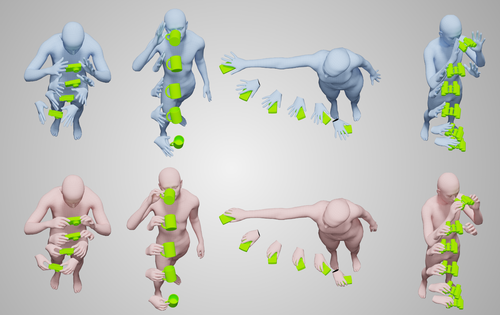
GRIP: Generating Interaction Poses Using Spatial Cues and Latent Consistency
Taheri, O., Zhou, Y., Tzionas, D., Zhou, Y., Ceylan, D., Pirk, S., Black, M. J.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings)

Adversarial Likelihood Estimation With One-Way Flows
Ben-Dov, O., Gupta, P. S., Abrevaya, V., Black, M. J., Ghosh, P.
In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages: 3779-3788, January 2024 (inproceedings)
2023

Controlling Text-to-Image Diffusion by Orthogonal Finetuning
Qiu*, Z., Liu*, W., Feng, H., Xue, Y., Feng, Y., Liu, Z., Zhang, D., Weller, A., Schölkopf, B.
Advances in Neural Information Processing Systems 36 (NeurIPS 2023), 36, pages: 79320-79362, (Editors: A. Oh and T. Neumann and A. Globerson and K. Saenko and M. Hardt and S. Levine), Curran Associates, Inc., December 2023, *equal contribution (conference)

Emotional Speech-Driven Animation with Content-Emotion Disentanglement
Daněček, R., Chhatre, K., Tripathi, S., Wen, Y., Black, M., Bolkart, T.
In ACM, December 2023 (inproceedings) Accepted
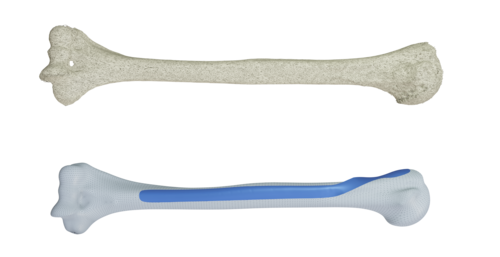
Optimizing the 3D Plate Shape for Proximal Humerus Fractures
Keller, M., Krall, M., Smith, J., Clement, H., Kerner, A. M., Gradischar, A., Schäfer, Ü., Black, M. J., Weinberg, A., Pujades, S.
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pages: 487-496, Springer, October 2023 (conference)
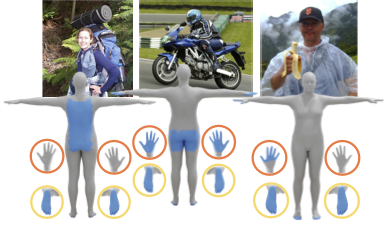
DECO: Dense Estimation of 3D Human-Scene Contact in the Wild
Tripathi, S., Chatterjee, A., Passy, J., Yi, H., Tzionas, D., Black, M. J.
In Proc. International Conference on Computer Vision (ICCV), October 2023 (inproceedings) Accepted
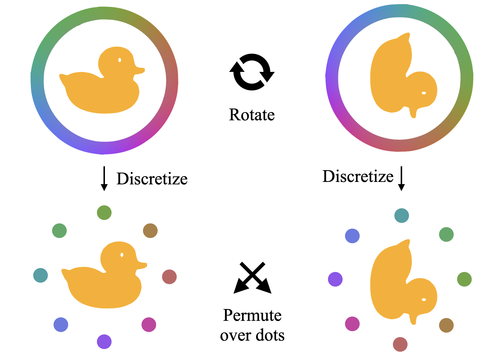
Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
(Oral)
Feng, H., Kulits, P., Liu, S., Black, M. J., Abrevaya, V. F.
In Proc. International Conference on Computer Vision (ICCV), October 2023 (inproceedings) To be published
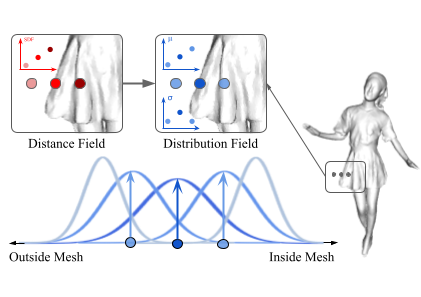
D-IF: Uncertainty-aware Human Digitization via Implicit Distribution Field
Yang, X., Luo, Y., Xiu, Y., Wang, W., Xu, H., Fan, Z.
In Proc. International Conference on Computer Vision (ICCV), October 2023 (inproceedings) Accepted

AG3D: Learning to Generate 3D Avatars from 2D Image Collections
Dong, Z., Chen, X., Yang, J., J.Black, M., Hilliges, O., Geiger, A.
In Proc. International Conference on Computer Vision (ICCV), October 2023 (inproceedings)
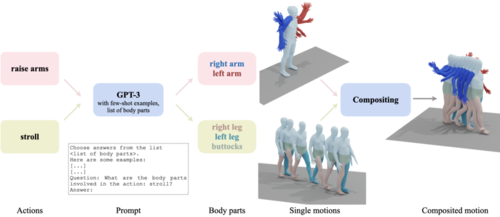
SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation
Athanasiou, N., Petrovich, M., Black, M. J., Varol, G.
In Proc. International Conference on Computer Vision (ICCV), pages: 9984-9995, October 2023 (inproceedings)
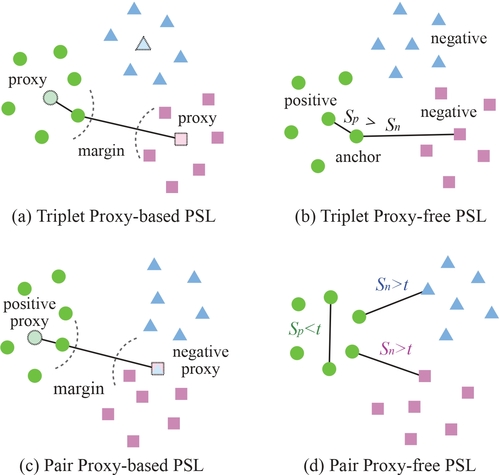
Pairwise Similarity Learning is SimPLE
Wen, Y., Liu, W., Feng, Y., Raj, B., Singh, R., Weller, A., Black, M. J., Schölkopf, B.
In Proc. International Conference on Computer Vision (ICCV), October 2023 (inproceedings) Accepted
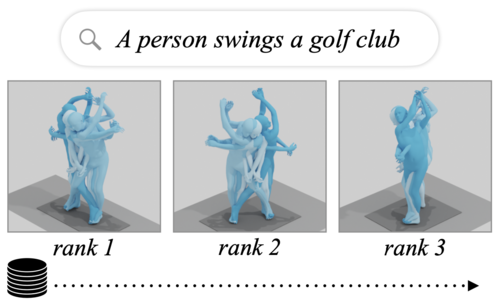
TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis
Petrovich, M., Black, M. J., Varol, G.
In Proc. International Conference on Computer Vision (ICCV), pages: 9488-9497, October 2023 (inproceedings)

Synthetic Data-Based Detection of Zebras in Drone Imagery

Synthesizing Physical Character-scene Interactions
Hassan, M., Guo, Y., Wang, T., Black, M., Fidler, S., Peng, X. B.
In SIGGRAPH Conf. Track, August 2023 (inproceedings)
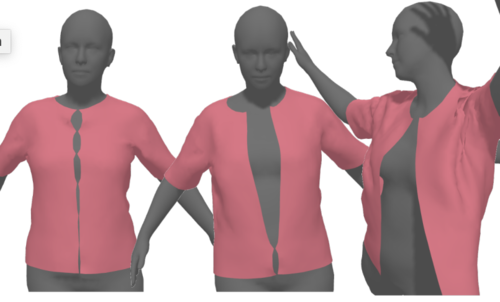
HOOD: Hierarchical Graphs for Generalized Modelling of Clothing Dynamics
Grigorev, A., Thomaszewski, B., Black, M. J., Hilliges, O.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 16965-16974, June 2023 (inproceedings)

High-Fidelity Clothed Avatar Reconstruction from a Single Image
Liao, T., Zhang, X., Xiu, Y., Yi, H., Liu, X., Qi, G., Zhang, Y., Wang, X., Zhu, X., Lei, Z.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 8662-8672, June 2023 (inproceedings) Accepted

ECON: Explicit Clothed humans Optimized via Normal integration
(Highlight Paper)
Xiu, Y., Yang, J., Cao, X., Tzionas, D., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 512-523, June 2023 (inproceedings) Accepted

Instant Volumetric Head Avatars
Zielonka, W., Bolkart, T., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2023 (inproceedings)

BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
(Highlight Paper)
Black, M. J., Patel, P., Tesch, J., Yang, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 8726-8737, June 2023 (inproceedings)

BITE: Beyond Priors for Improved Three-D Dog Pose Estimation
Rüegg, N., Tripathi, S., Schindler, K., Black, M. J., Zuffi, S.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 8867-8876, June 2023 (inproceedings)

MIME: Human-Aware 3D Scene Generation
Yi, H., Huang, C. P., Tripathi, S., Hering, L., Thies, J., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 12965-12976, June 2023 (inproceedings) Accepted

Learning from synthetic data generated with GRADE
Bonetto, E., Xu, C., Ahmad, A.
In ICRA 2023 Pretraining for Robotics (PT4R) Workshop, June 2023 (inproceedings) Accepted

PointAvatar: Deformable Point-Based Head Avatars From Videos
Zheng, Y., Yifan, W., Wetzstein, G., Black, M. J., Hilliges, O.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 21057-21067, June 2023 (inproceedings)
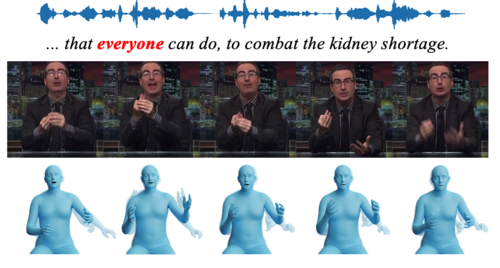
Generating Holistic 3D Human Motion from Speech
Yi, H., Liang, H., Liu, Y., Cao, Q., Wen, Y., Bolkart, T., Tao, D., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 469-480, June 2023 (inproceedings) Accepted

TRACE: 5D Temporal Regression of Avatars With Dynamic Cameras in 3D Environments
Sun, Y., Bao, Q., Liu, W., Mei, T., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 8856-8866, June 2023 (inproceedings)

Simulation of Dynamic Environments for SLAM
Bonetto, E., Xu, C., Ahmad, A.
In ICRA 2023 Workshop on the Active Methods in Autonomous Navigation, June 2023 (inproceedings) Accepted
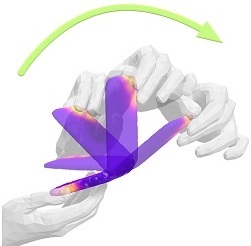
ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M. J., Hilliges, O.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 12943-12954, June 2023 (inproceedings) Accepted

Reconstructing Signing Avatars from Video Using Linguistic Priors
Forte, M., Kulits, P., Huang, C. P., Choutas, V., Tzionas, D., Kuchenbecker, K. J., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 12791-12801, June 2023 (inproceedings)

3D Human Pose Estimation via Intuitive Physics
Tripathi, S., Müller, L., Huang, C. P., Taheri, O., Black, M., Tzionas, D.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR) , pages: 4713-4725, June 2023 (inproceedings) Accepted

Instant Multi-View Head Capture through Learnable Registration
Bolkart, T., Li, T., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 768-779, June 2023 (inproceedings)

SLOPER4D: A Scene-Aware Dataset for Global 4D Human Pose Estimation in Urban Environments
Yudi, D., Yitai, L., Xiping, L., Chenglu, W., Lan, X., Hongwei, Y., Siqi, S., Yuexin, M., Cheng, W.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 682-692, CVF, June 2023 (inproceedings) Accepted

Detecting Human-Object Contact in Images
Chen, Y., Dwivedi, S. K., Black, M. J., Tzionas, D.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 17100-17110, June 2023 (inproceedings) Accepted

MeshDiffusion: Score-based Generative 3D Mesh Modeling
(Notable-Top-25%)
Liu, Z., Feng, Y., Black, M. J., Nowrouzezahrai, D., Paull, L., Liu, W.
Proceedings of the Eleventh International Conference on Learning Representations (ICLR), May 2023 (conference)
2022
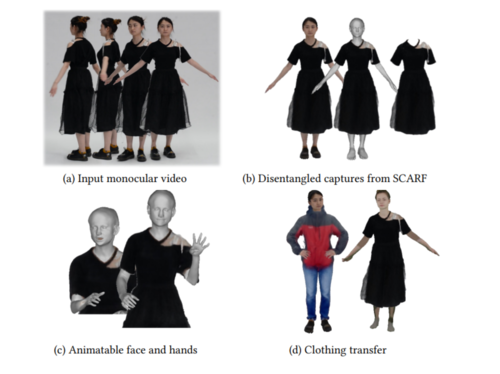
Capturing and Animation of Body and Clothing from Monocular Video
Feng, Y., Yang, J., Pollefeys, M., Black, M. J., Bolkart, T.
In SIGGRAPH Asia 2022 Conference Papers, pages: 1-9, SA’22, December 2022 (inproceedings)

DART: Articulated Hand Model with Diverse Accessories and Rich Textures
Gao*, D., Xiu*, Y., Li*, K., Yang*, L., Wang, F., Zhang, P., Zhang, B., Lu, C., Tan, P.
Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS), November 2022 (conference) In press

Towards Metrical Reconstruction of Human Faces
Zielonka, W., Bolkart, T., Thies, J.
In Computer Vision – ECCV 2022, 13, pages: 250-269, Lecture Notes in Computer Science, 13673, (Editors: Avidan, Shai and Brostow, Gabriel and Cissé, Moustapha and Farinella, Giovanni Maria and Hassner, Tal), Springer, Cham, October 2022 (inproceedings)

Deep Residual Reinforcement Learning based Autonomous Blimp Control
Liu, Y. T., Price, E., Black, M., Ahmad, A.
2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2022), pages: 12566-12573, IEEE, Piscataway, NJ, October 2022 (conference)

Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
Feng, H., Bolkart, T., Tesch, J., Black, M. J., Abrevaya, V. F.
In Computer Vision – ECCV 2022, 13, pages: 72-90, Lecture Notes in Computer Science, 13673, (Editors: Avidan, Shai and Brostow, Gabriel and Cissé, Moustapha and Farinella, Giovanni Maria and Hassner, Tal), Springer, Cham, October 2022 (inproceedings)

Learning to Fit Morphable Models
Choutas, V., Bogo, F., Shen, J., Valentin, J.
In Computer Vision – ECCV 2022, 6, pages: 160-179, Lecture Notes in Computer Science, 13666, (Editors: Avidan, Shai and Brostow, Gabriel and Cissé, Moustapha and Farinella, Giovanni Maria and Hassner, Tal), Springer, Cham, October 2022 (inproceedings)

SUPR: A Sparse Unified Part-Based Human Representation
Osman, A. A. A., Bolkart, T., Tzionas, D., Black, M. J.
In Computer Vision – ECCV 2022, 2, pages: 568-585, Lecture Notes in Computer Science, 13662, (Editors: Avidan, Shai and Brostow, Gabriel and Cissé, Moustapha and Farinella, Giovanni Maria and Hassner, Tal), Springer, Cham, October 2022 (inproceedings)
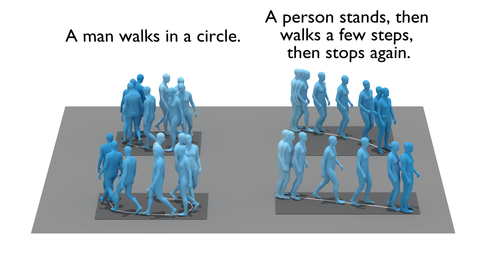
TEMOS: Generating diverse human motions from textual descriptions
Petrovich, M., Black, M. J., Varol, G.
In European Conference on Computer Vision (ECCV), pages: 48-497, Springer International Publishing, October 2022 (inproceedings)