2022

Reconstructing Expressive 3D Humans from RGB Images
2021
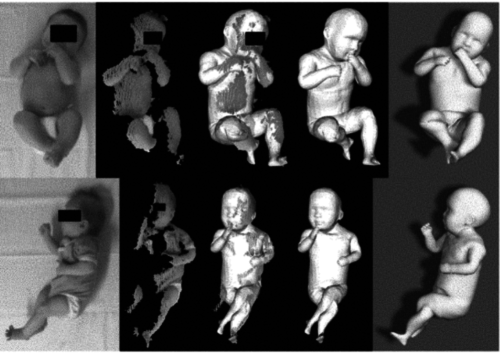
Skinned multi-infant linear body model
Hesse, N., Pujades, S., Romero, J., Black, M.
(US Patent 11,127,163, 2021), September 2021 (patent)
2020
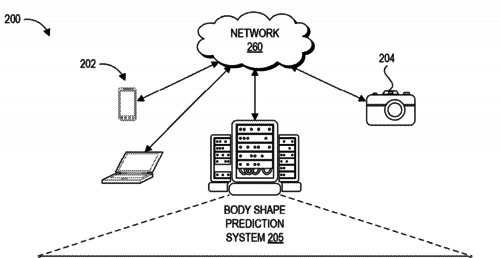
Machine learning systems and methods of estimating body shape from images
Black, M., Rachlin, E., Heron, N., Loper, M., Weiss, A., Hu, K., Hinkle, T., Kristiansen, M.
(US Patent 10,679,046), June 2020 (patent)
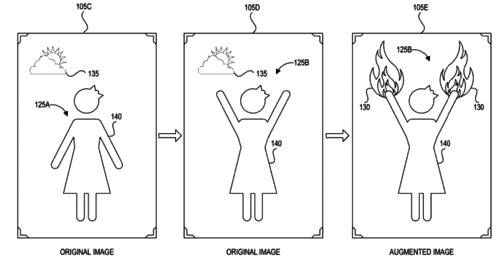
Machine learning systems and methods for augmenting images
Black, M., Rachlin, E., Lee, E., Heron, N., Loper, M., Weiss, A., Smith, D.
(US Patent 10,529,137 B1), January 2020 (patent)
2019
Method for providing a three dimensional body model
Loper, M., Mahmood, N., Black, M.
September 2019, U.S.~Patent 10,417,818 (patent)

2018

Method and Apparatus for Estimating Body Shape
Black, M. J., Balan, A., Weiss, A., Sigal, L., Loper, M., St Clair, T.
June 2018, U.S.~Patent 10,002,460 (patent)
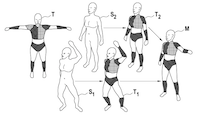
Co-Registration – Simultaneous Alignment and Modeling of Articulated 3D Shapes
Black, M., Hirshberg, D., Loper, M., Rachlin, E., Weiss, A.
February 2018, U.S.~Patent 9,898,848 (patent)
2017
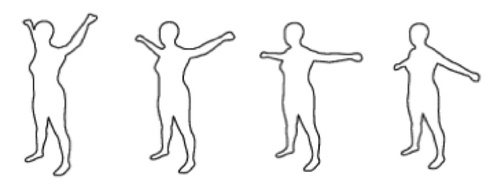
Parameterized Model of 2D Articulated Human Shape
Black, M. J., Freifeld, O., Weiss, A., Loper, M., Guan, P.
September 2017, U.S.~Patent 9,761,060 (patent)
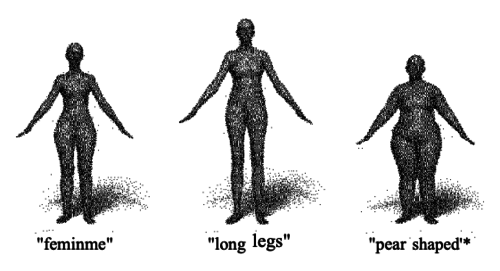
Crowdshaping Realistic 3D Avatars with Words
Streuber, S., Ramirez, M. Q., Black, M., Zuffi, S., O’Toole, A., Hill, M. Q., Hahn, C. A.
August 2017, Application PCT/EP2017/051954 (patent)
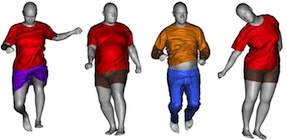
System and method for simulating realistic clothing
2016
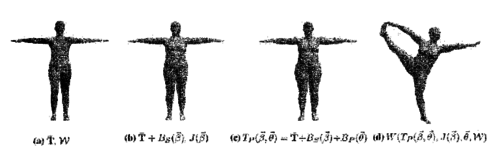
Skinned multi-person linear model
Black, M.J., Loper, M., Mahmood, N., Pons-Moll, G., Romero, J.
December 2016, Application PCT/EP2016/064610 (patent)

2015

Proceedings of the 37th German Conference on Pattern Recognition
Gall, J., Gehler, P., Leibe, B.
Springer, German Conference on Pattern Recognition, October 2015 (proceedings)
2014

Advanced Structured Prediction
Nowozin, S., Gehler, P. V., Jancsary, J., Lampert, C. H.
Advanced Structured Prediction, pages: 432, Neural Information Processing Series, MIT Press, November 2014 (book)

Learning People Detectors for Tracking in Crowded Scenes.
Tang, S., Andriluka, M., Milan, A., Schindler, K., Roth, S., Schiele, B.
2014, Scene Understanding Workshop (SUNw, CVPR workshop) (unpublished)

Human Pose Estimation from Video and Inertial Sensors
2013

Human Pose Calculation from Optical Flow Data
System and method for generating bilinear spatiotemporal basis models
Matthews, I. A. I. S. T. S. K. S. Y.
US Patent Application 13/425,369, March 2013 (patent)
A Study of X-Ray Image Perception for Pneumoconiosis Detection
2012
An Analysis of Successful Approaches to Human Pose Estimation

Consumer Depth Cameras for Computer Vision - Research Topics and Applications
Fossati, A., Gall, J., Grabner, H., Ren, X., Konolige, K.
Advances in Computer Vision and Pattern Recognition, Springer, 2012 (book)
2008

GNU Octave Manual Version 3
John W. Eaton, David Bateman, Soren Hauberg
Network Theory Ltd., October 2008 (book)
2005
Visual motion analysis method for detecting arbitrary numbers of moving objects in image sequences
Jepson, A. D., Fleet, D. J., Black, M. J.
US Pat. 6,954,544, October 2005 (patent)

A Flow-Based Approach to Vehicle Detection and Background Mosaicking in Airborne Video
2003
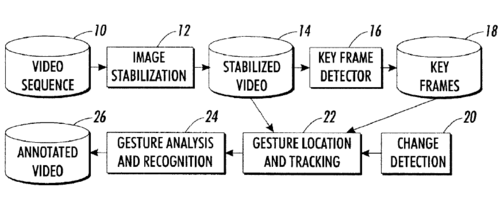
Method and apparatus for generating a condensed version of a video sequence including desired affordances
Black, M. J., Ju, S., Minneman, S., Kimber, D.
US Pat. 6,560,281, May 2003 (patent)
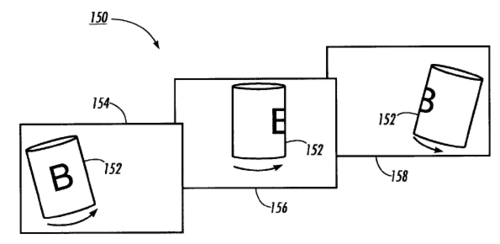
Apparatus and method for identifying and tracking objects with view-based representations
Black, M. J., Jepson, A.
US Pat. 6,526,156, February 2003 (patent)
1995
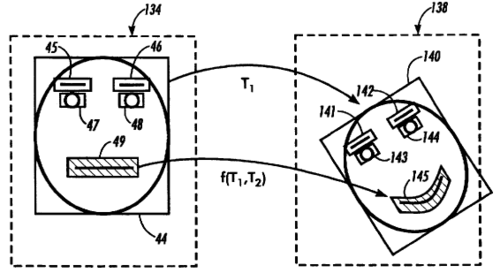
Apparatus and method for tracking facial motion through a sequence of images
Black, M. J., Yacoob, Y.
US Pat. 5,802,220, December 1995 (patent)
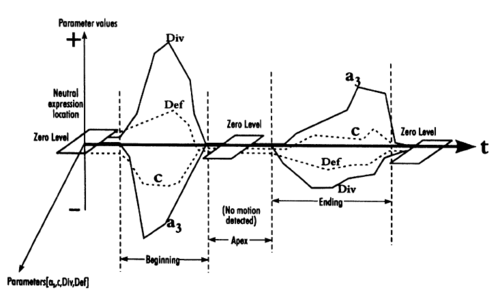
Apparatus and method for recognizing facial expressions and facial gestures in a sequence of images
Black, M. J., Yacoob, Y.
US Pat. 5,774,591, December 1995 (patent)
Image segmentation using robust mixture models
Black, M. J., Jepson, A. D.
US Pat. 5,802,203, June 1995 (patent)