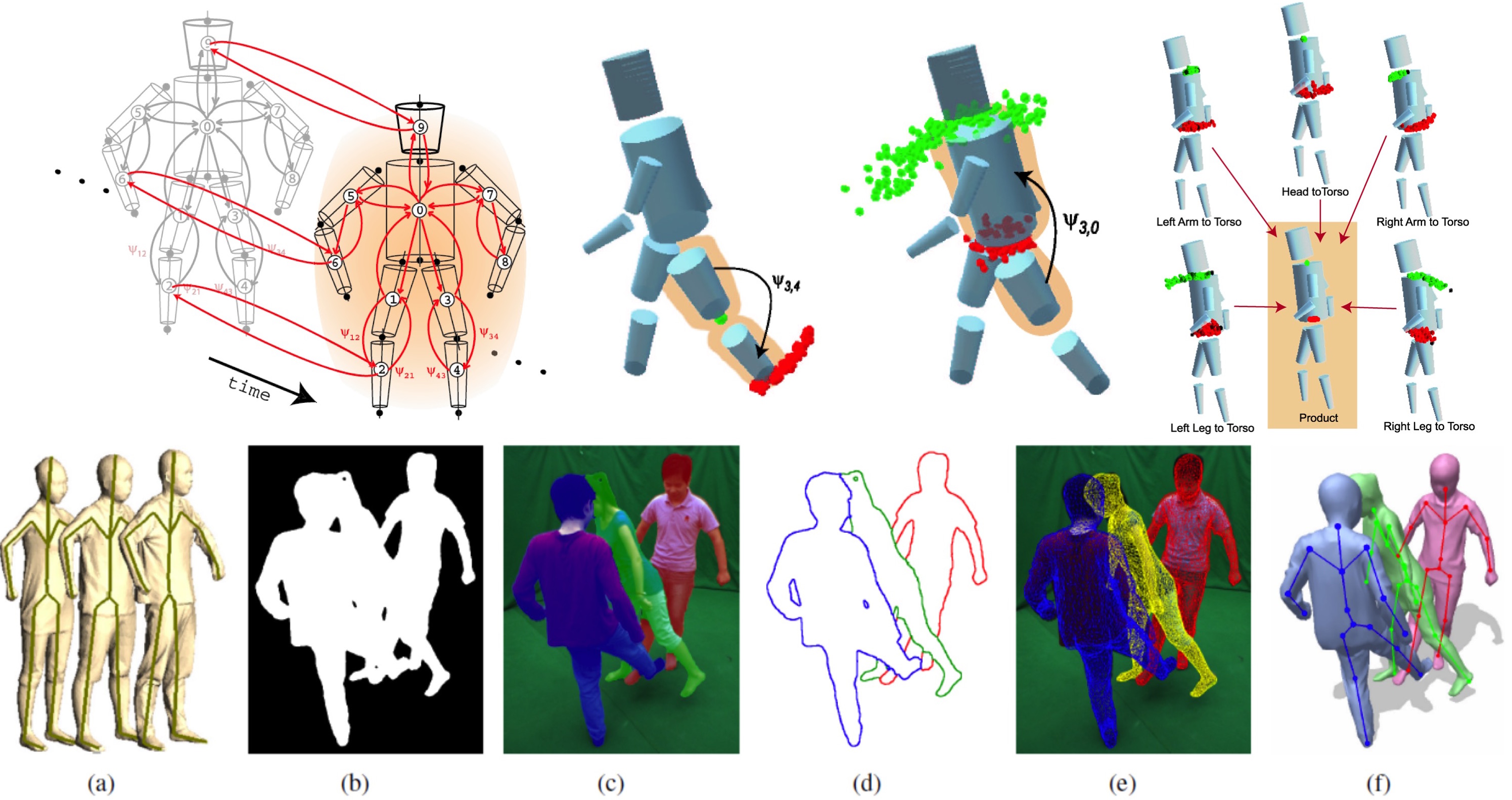
Top row: (left) In [ ], bodies are represented by a part-based graphical model in space and time. (middle) Messages between parts are represented by particles. (right) Non-parametric belief propagation computes message products. Bottom row: In [ ], we segment and fit bodies multi-camera images. (a) Articulated template models. (b) Input silhouettes. (c) Segmentation. (d) Contour labels assigned to each person. (e) Estimated surface. (f) Estimated 3D models with embedded skeletons.
While multi-camera video data facilitates markerless motion capture, many challenges remain.
We formulate the problem of 3D human pose estimation and tracking as inference in a graphical model [ ]. The body is modeled as a collection of loosely-connected body-parts (a 3D pictorial structure) using an undirected graphical model in which nodes correspond to parts and edges to kinematic, penetration, and temporal constraints. These constraints are encoded using pair-wise statistical distributions, learned from mocap data. Human pose and motion are computed using Particle Message Passing, a form of non-parametric belief propagation that can be applied over graphical models with loops. The loose-limbed model and decentralized graph structure allow us to incorporate "bottom-up" visual cues, such as limb and head detectors into the inference process. These detectors enable automatic initialization and aid recovery from transient tracking failures.
Capturing the skeleton motion and detailed time-varying surface geometry of multiple, closely interacting persons is harder still, even in a multi-camera setup, due to frequent occlusions and ambiguities in feature-to-person assignments. To address this, we propose a framework that exploits multi-view image segmentation [ ]. To this end, a probabilistic shape and appearance model is employed to segment the input images and to assign each pixel uniquely to one person. Given the articulated template models of each person and the labeled pixels, a combined optimization scheme, which splits the skeleton pose optimization problem into a local one and a lower dimensional global one, is applied one-by-one to each individual, followed by surface estimation to capture detailed non-rigid deformations. Our approach can capture the 3D motion of humans accurately even if they move rapidly, wear apparel, and engage in challenging multi-person motions.