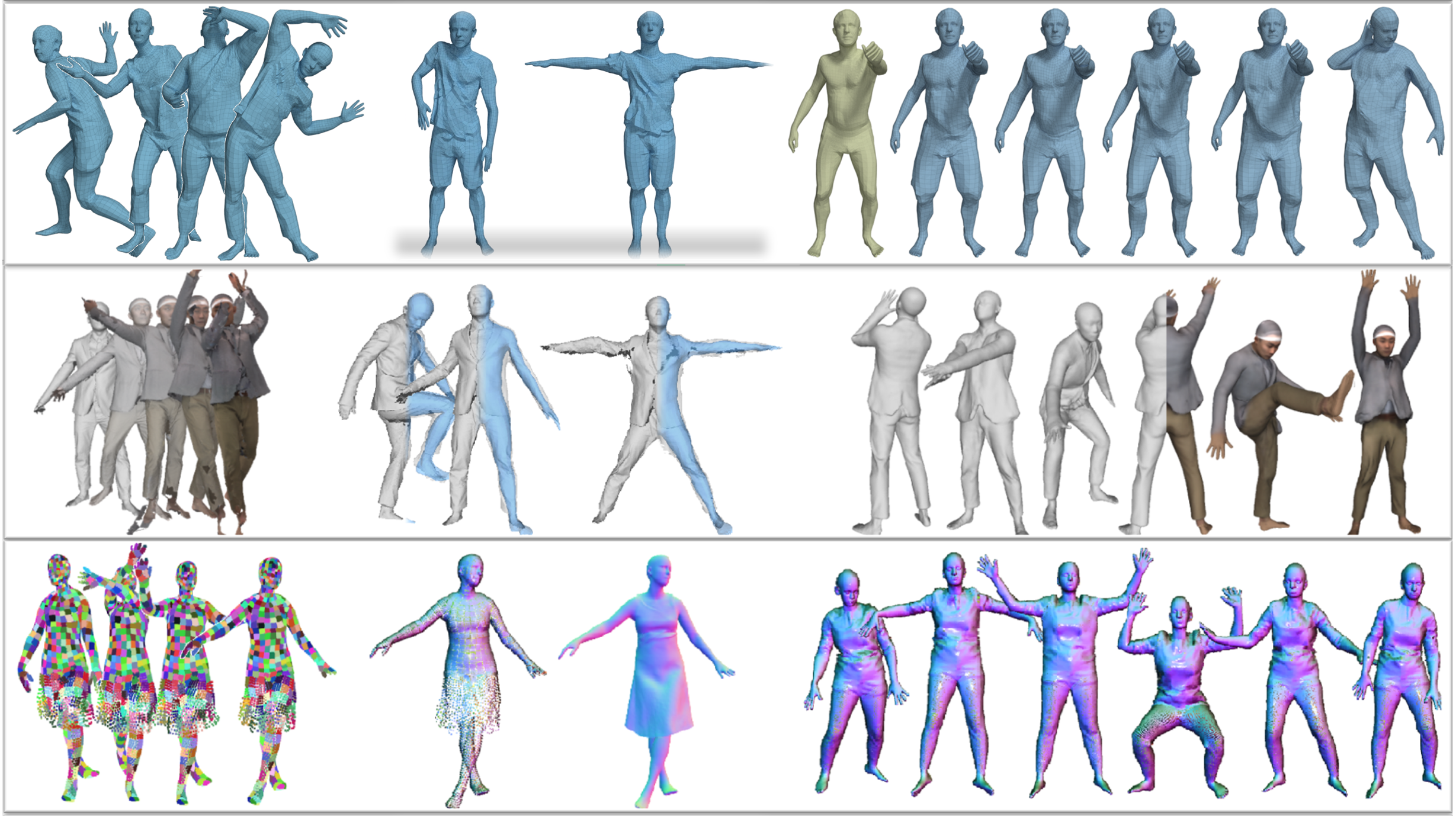
We explore different 3D shape representations to model clothed humans: mesh (top row), implicit function (middle row), and point cloud (bottom row)
While body models like SMPL lack clothing, people in images and videos are typically clothed. Modeling clothing on the body is hard, because of the variety of garments, varied topology of clothing, and the complex physical properties of cloth. Standard methods to dress 3D bodies rely on 2D patterns and physics simulation. Such approaches require expert knowledge and are labor intensive. We seek to capture garments on people "in the wild" and then realistically animate them. Consequently, we take a data-driven approach to learn the shape of clothed humans.
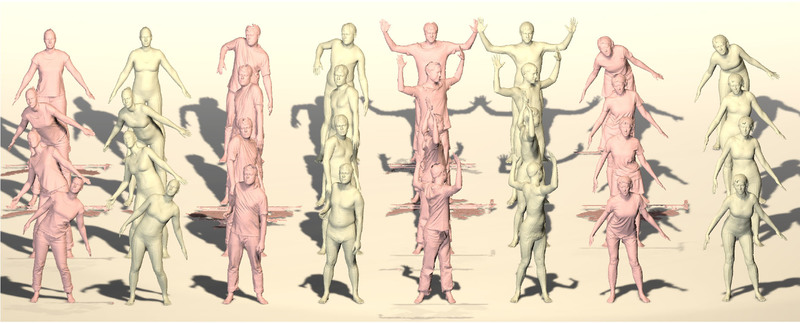
To learn a model of 3D clothing, we use both synthetic data from clothing simulation [ ] and scans captured in our 4D body scanner [ ]. We estimate the body shape under the clothing using BUFF [ ] and then model how clothing deviates from the body.
With this data, we learn how clothing deforms with body pose. For example, CAPE [ ] uses a conditional mesh-VAE-GAN, that is conditioned on pose, to learn clothing deformation from the SMPL body model. CAPE can then add pose-dependent clothing deformation to an animated SMPL body.
CAPE requires registered 3D meshes, which are challenging to obtain for clothing, and is tied to the topology of SMPL. To address these issues, we use implicit surface models. SCANimate [ ] takes raw 3D scans are un-poses them to a canonical pose with the help of the estimated underlying body as well as a novel cycle-consistency loss. The canonicalized scans are then used to learn an implicit shape model that extends linear blend skinning to blend fields, defined implicitly in 3D space.
Implicit models lack compatibility with standard graphics pipelines. To address that, we propose two models, SCALE [ ] and POP [ ], that are based on point clouds and extend deep point cloud representations to deal with articulated human pose. The points are explicit but the surface through them is implicit. POP goes beyond previous methods to model multiple garments, enabling the creation of an animatable avatar, with pose-dependent deformations, from a single scan. These point-based models are readily rendered as images using neural rendering methods; see Neural Rendering for more information.
SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes (ICCV 2021) [ ]
The Power of Points for Modeling Humans in Clothing (ICCV 2021) [ ]
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements (CVPR 2021) [ ]
SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks (CVPR 2021) [ ]
Learning to Dress 3D People in Generative Clothing (CVPR 2020) [ ]
ClothCap (SIGGRAPH 2017) [ ]
Estimating Body Shape under Clothing (CVPR 2017) [ ]
CAPE: Clothed Auto Person Encoding
Raw scans, registered meshes, and fitted bodies.
Go to the official webpage.

BUFF: Bodies Under Flowing Fashion
Raw scans of clothed human and fitted bodies.
Go to the official webpage.