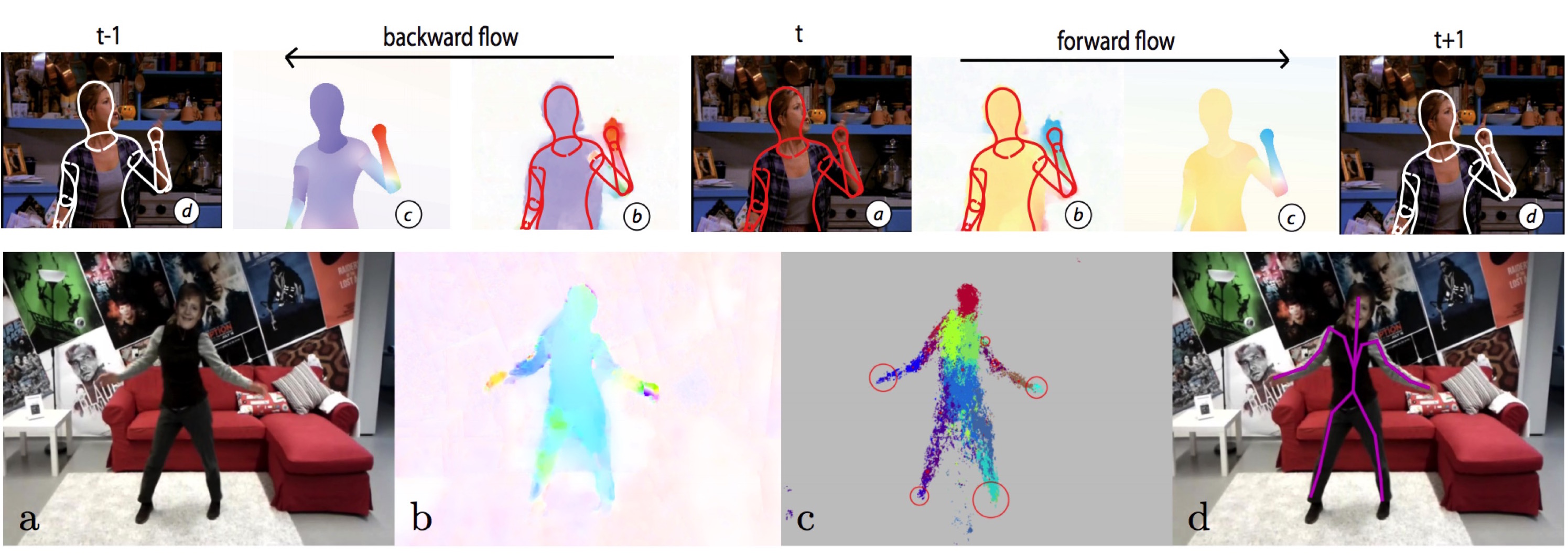
Top row: Flowing puppets. (a) Frame with a hypothesized human “puppet” model. (b) Dense flow between frame (a) and its neighboring frames. (c) The flow of the puppet is approximated by a part-based affine model. (d) Prediction of the puppet from (a) into the adjacent frames using the estimated flow. Bottom Row: FlowCap. (a) Example frame from a video sequence shot with a phone camera. (b) Optical flow. (c) Per-pixel part assignments based on flow with overlaid uncertainty ellipses (red). (d) Predicted 2D part centroids connected in a tree.
Much of the work on human pose estimation focuses on still images. We argue that there is much to be gained by looking at video sequences and, specifically, using optical flow. Flow tells us what goes with what over time. This allows the temporal propagation of information, which can reduce uncertainty in pose estimation. Flow also provides strong cues about objects in the scene, their boundaries, and how they move. We find that optical flow algorithms are now good enough to play an important role in human pose estimation.
Inferring pose over a video sequence is advantageous because poses of people in adjacent frames exhibit properties of smooth variation due to the nature of human and camera motion. Here we make a simple observation: Information about how a person moves from frame to frame is present in the optical flow field. We develop an approach for tracking articulated motions that "links" articulated shape models of people in adjacent frames trough the dense optical flow [ ]. Key to this approach is a 2D shape model of the body [ ] that we use to compute how the body moves over time. The resulting "flowing puppets" integrate image evidence across frames to improve pose inference.
Dense optical flow provides information about 2D body pose [ ]. Like range data, flow is largely invariant to appearance but unlike depth it can be directly computed from monocular video. We demonstrate that body parts can be detected from dense flow alone using the same random forest approach used by the Microsoft Kinect. Unlike range data, when people stop moving, there is no optical flow and they effectively disappear. To address this, our FlowCap method uses a Kalman filter to propagate body part positions and velocities over time and a regression method to predict 2D body pose from part centers from only monocular video of people moving.
Finally in [ ] we explore the importance of optical flow for human activity recognition. We create a novel dataset of complex video sequences with ground truth 2D pose and flow using our deformable structures model [ ]. We find that optical flow can play an important role in human action recognition.