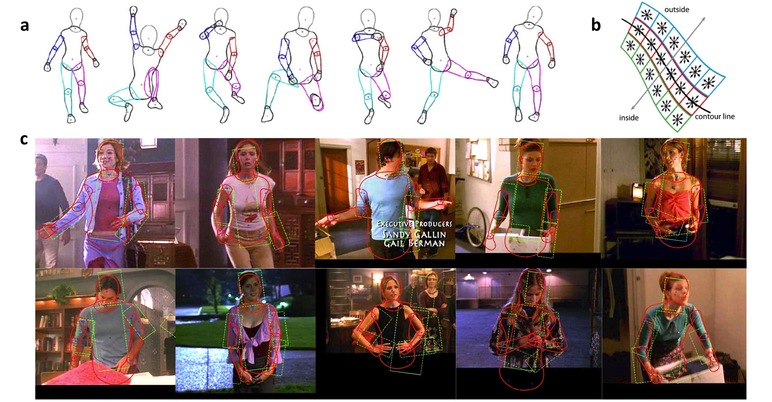
a. Examples of the DS model in a variety of poses. Note how much the model’s left calf (magenta) varies in shape. b. Contour likelihood. The image shows the location of the HOG cells along a limb contour. Cells are located on the boundary, just inside, and just outside. c. Estimated body pose – examples where the DS model improves on the PS baseline. DS is solid red, PS is dashed green.
We address the problem of estimating the pose of people in images and video using a new deformable 2D model of the human body.
The prevailing approach to this problem uses Pictorial Structures (PS) models, which define a probabilistic model of 2D articulated objects in images. Typical PS models assume an object can be represented by a set of rigid parts connected with pairwise constraints that define the prior probability of part configurations. Such 2D models cannot capture how the shape of 3D articulated objects varies with pose when projected into the image. To address this, PS parts are sometimes augmented with an additional scale parameter to account for foreshortening, but typically this scale parameter is not correlated with the pose prior.
Additionally, these models are widely used to represent non-rigid articulated objects such as humans and animals despite the fact that such objects have parts that deform non-rigidly. While PS models are often called deformable, the deformation is in terms of the relative spatial arrangement of the parts. In general, however, the parts of natural articulated objects vary in shape as a function of their spatial arrangement. For example, rotation of a human upper arm causes changes in shoulder shape.
To address this, we define a new Deformable Structures (DS) model that is a natural extension of previous PS models and that captures the non-rigid shape deformation of the parts. DS shares with PS a simliar parameterization but, instead of using fixed templates for the parts, each part in a DS model is represented by a low-dimensional shape deformation space. Pairwise potentials capture how a part's shape varies with relative pose and the shape of the neighboring parts.
This model is learned from a detailed 3D graphics model of the human body. This allows us to generate training data of arbitrary poses for arbitrary camera locations by projecting the model contours and joint locations into the 2D image. Using Principal Component Analysis, we learn the DS model from random poses and for random cameras using an approximately frontal view, but models for other poses or scenarios can also be learned. Currently our DS models are learned from a single 3D human body shape but future work should address models of people of varying shape.
A key advantage of the DS model is that it more accurately models object boundaries. This enables contour-based and region-based image likelihood models that are more discriminative than previous PS likelihoods. We learn likelihood models using training imagery annotated using a DS “puppet.” With this puppet we define a novel annotation tool for the web annotation of human pose in images and videos. Since body shape is made explicit in the prior, the likelihood does not need to represent how image appearance varies with shape. This simplifies the job of the likelihood term.
The part-based structure of the DS model allows us to infer human poses in images using a form of non-parametric belief propagation. We evaluate performance in 2D human pose estimation on the Buffy the Vampire Slayer data set. Finally, while we develop the model in the context of 2D human body pose and shape, the model itself is fully general and can be used to represent other articulated objects with non-rigidly deforming parts.
Future work:
1. The DS model is a “naked” puppet, and future extensions of the model can go in the direction of learning a generative model with richer appearance: a probabilistic model for the contour location expressing the uncertainty over the type of clothing and hairstyle can be exploited in methods that couple pose estimation with image segmentation.
2. We do not explicitly distinguish in the model between deformations due to pose and deformations due to camera variations. Adding to the model a parametrization for the camera location could be an interesting future direction for modeling shape changes in video sequences with moving camera.
3. In many applications one would like to estimate 3D pose from 2D. The correlation between 2D pose and shape and 3D pose can be learned from the DS training set since 3D pose information is already available from the training samples generated from the 3D model projection.
Deformable Structures Model in Matlab
Pose Estimation on the Buffy dataset exploiting the Flexible Mixtures of Parts model